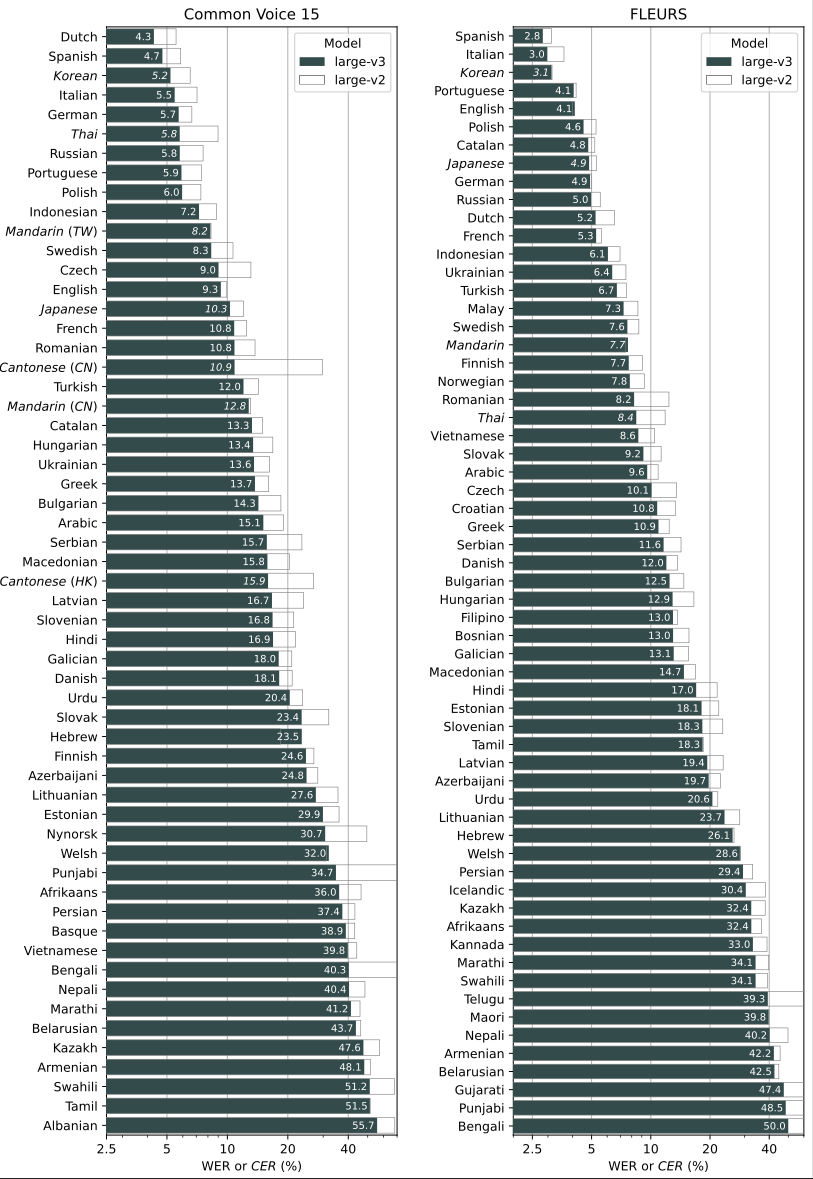
Deze grafieken tonen hoe goed verschillende spraakmodellen audio omzetten naar tekst in diverse talen. Elke taal heeft twee balkjes: één voor model large‑v3 en één voor large‑v2. Het percentage naast de balk geeft aan hoeveel fouten het model maakt (WER of CER). Hoe lager het percentage, hoe beter de herkenning. Door de lengte van de balkjes te vergelijken zie je direct welk model beter presteert. De twee grafieken horen bij verschillende datasets, zodat je een compleet beeld krijgt van de prestaties per taal.